Examples¶
Contents
Regression¶
“Allstate claims severity” dataset
conf.py¶
"""Regression model tuning example.
https://www.kaggle.com/c/allstate-claims-severity
Ideas:
* estimator: linear vs lightgbm vs xgboost.
* features 'yeo-johnson' transformation.
* features quantile scaler.
* polynomial feature generation: degree 1 vs 2.
* target transformer: None vs np.log vs y**0.25.
* loss: mse vs mae vs `ln(cosh(x)).
* estimator hyper-parameters.
Current configuration:
* use 10000 rows subset of train and test.
* use lgbm with 'fair' objective.
* use target y**0.25 transformation and features 'yeo-johnson' transformation.
* optimize polynomial degree and 'yeo-johnson'.
"""
import lightgbm
import mlshell
import numpy as np
import pycnfg
import sklearn
def target_func(y):
return y**0.25
def target_inverse_func(y):
return y**4
# Create target transformers (avoid lambda function).
target_transformer = sklearn.preprocessing.FunctionTransformer(
func=target_func, inverse_func=target_inverse_func,)
target_transformer_2 = sklearn.preprocessing.FunctionTransformer(
func=np.log, inverse_func=np.exp)
# Set hp ranges for optimize.
hp_grid = {
'process_parallel__pipeline_numeric__transform_normal__skip': [True, False],
'process_parallel__pipeline_numeric__add_polynomial__degree': [1, 2],
'estimate__transformer': [target_transformer],
# lgbm
# 'estimate__regressor__n_estimators': np.linspace(50, 1000, 10, dtype=int),
# 'estimate__regressor__num_leaves': [2**i for i in range(1, 6 + 1)],
# 'estimate__regressor__min_data_in_leaf': np.linspace(1, 100, 10, dtype=int),
# 'estimate__regressor__min_data_in_leaf': scipy.stats.randint(1, 100),
# 'estimate__regressor__max_depth': np.linspace(1, 30, 10, dtype=int),
}
CNFG = {
'pipeline': {
'sgd': {
'estimator': sklearn.linear_model.SGDRegressor(
penalty='elasticnet', l1_ratio=0.01, alpha=0.01,
shuffle=False, max_iter=1000, early_stopping=True,
learning_rate='invscaling', power_t=0.25, eta0=0.01,
verbose=1, random_state=42),
},
'lgbm': {
'estimator': lightgbm.LGBMRegressor(
objective='fair', num_leaves=2, min_data_in_leaf=1,
n_estimators=250, max_depth=-1, silent=False,
random_state=42),
},
},
'metric': {
'r2': {
'score_func': sklearn.metrics.r2_score,
'kwargs': {'greater_is_better': True},
},
'mae': {
'score_func': sklearn.metrics.mean_absolute_error,
'kwargs': {'greater_is_better': False},
},
},
'dataset': {
# Section level 'global' to specify common kwargs for test and train.
'global': {'targets_names': ['loss'],
'categor_names': [f'cat{i}' for i in range(1, 117)],
'load__kwargs': {'nrows': 10000, 'index_col': 'id'},
},
'train': {
'filepath': './data/train.csv',
'split__kwargs': {'train_size': 0.7, 'shuffle': False},
},
'test': {
'filepath': 'data/test.csv',
'split__kwargs': {'train_size': 1},
},
},
'workflow': {
'conf': {
# Global values will replace kwargs in corresponding default steps
# => easy switch between pipeline for example (pycnfg move unknown
# keys to 'global' by default).
'pipeline_id': 'pipeline__lgbm',
'dataset_id': 'dataset__train',
'predict__dataset_id': 'dataset__test',
'hp_grid': hp_grid,
'gs_params': 'gs_params__conf',
'metric_id': ['metric__mae', 'metric__r2'],
'steps': [
('optimize',),
('validate',),
('predict',),
('dump',),
],
},
},
# Separate section for 'gs_params' kwarg.
'gs_params': {
'conf': {
'priority': 3,
'init': {
'n_iter': None,
'n_jobs': 1,
'refit': 'metric__mae',
'cv': sklearn.model_selection.KFold(n_splits=3,
shuffle=True,
random_state=42),
'verbose': 1000,
'pre_dispatch': 'n_jobs',
'return_train_score': True,
},
},
},
}
if __name__ == '__main__':
# Use default configuration :data:`mlshell.CNFG`, that has pre-defined path
# logger sections and main sub-keys (see below)
objects = pycnfg.run(CNFG, dcnfg=mlshell.CNFG)
Classification¶
“IEEE fraud detection” dataset
conf.py¶
"""Classification model tuning example.
https://www.kaggle.com/c/ieee-fraud-detection
Current configuration:
* use 10000 rows subset of train and test.
* use lgbm.
* custom metric example to pass_custom__kw_args.
* three-stage optimization:
1. default mlshell.model_selection.RandomizedSearchOptimizer on 'roc_auc':
hp: 'estimate__classifier__num_leaves'.
2. efficient mlshell.model_selection.MockOptimizer on custom metric:
hp: 'estimate__apply_threshold__threshold' to grid search classification
threshold. Test values (10 samples) auto sampled from ROC curve plotted
on first stage best estimator`s predictions.
3. efficient mlshell.model_selection.MockOptimizer on custom metric:
hp: 'pass_custom__kw_args' to pass kwargs in custom metric. Could be use
to brute force arbitrary parameters (as if additional nested loops).
"""
import lightgbm
import mlshell
import numpy as np
import pycnfg
import sklearn
import pandas as pd
# Set hp ranges for optimization stage 1.
hp_grid_1 = {
# lgbm
'estimate__predict_proba__classifier__num_leaves': [2**i for i in range(1, 5 + 1)],
# 'estimate__classifier__n_estimators': np.linspace(50, 1000, 10, dtype=int),
# 'estimate__classifier__min_child_samples': scipy.stats.randint(1, 100),
# 'estimate__classifier__max_depth': np.linspace(1, 30, 10, dtype=int),
}
# Set hp ranges for optimization stage 2.
hp_grid_2 = {
'estimate__apply_threshold__threshold': 'auto', # Auto-resolving.
}
# Set hp ranges for optimization stage 3.
hp_grid_3 = {
'pass_custom__kw_args': [
{'metric__custom': {'param_a': 1, 'param_b': 'c'}},
{'metric__custom': {'param_a': 2, 'param_b': 'd'}}
],
}
def custom_score_metric(y_true, y_pred, **kw_args):
"""Custom precision metric with kw_args supporting."""
if kw_args:
# `pass_custom_kw_args` are passed here.
# some logic.
print(f"Custom metric kw_args: {kw_args}", flush=True)
tp = np.count_nonzero((y_true == 1) & (y_pred == 1))
fp = np.count_nonzero((y_true == 0) & (y_pred == 1))
score = tp/(fp+tp) if tp+fp != 0 else 0
return score
def merge(self, dataset, left_id, right_id, **kwargs):
"""Patch to DatasetProducer, add step to merge dataframe."""
left = dataset[left_id]
right = dataset[right_id]
raw = pd.merge(left, right, **kwargs)
# test dataset contains mistakes in column names.
raw.columns = [i.replace('-', '_') for i in raw.columns]
dataset['data'] = raw
return dataset
CNFG = {
'pipeline': {
'sgd': {
'estimator': sklearn.linear_model.SGDClassifier(
penalty='elasticnet', l1_ratio=0.01, alpha=0.01,
shuffle=False, max_iter=1000, early_stopping=True,
learning_rate='invscaling', power_t=0.25, eta0=0.01,
verbose=1, random_state=42),
'kwargs': {'th_step': True}
},
'lgbm': {
'estimator': lightgbm.LGBMClassifier(
colsample_bytree=0.9,
learning_rate=0.03, max_depth=13,
min_child_samples=1, min_child_weight=0.001,
min_split_gain=0.0, n_estimators=500, n_jobs=-1,
num_leaves=32, objective='binary',
random_state=42, reg_alpha=0.3,
reg_lambda=0.3, silent=True, subsample=0.9,
subsample_for_bin=200000, subsample_freq=3),
'kwargs': {'th_step': True}
},
},
'metric': {
'roc_auc': {
'score_func': sklearn.metrics.roc_auc_score,
'kwargs': {'greater_is_better': True, 'needs_proba': True},
},
'precision': {
'score_func': sklearn.metrics.precision_score,
'kwargs': {'greater_is_better': True, 'zero_division': 0,
'pos_label': 1}
},
'custom': {
'score_func': custom_score_metric,
'kwargs': {'greater_is_better': True, 'needs_custom_kw_args': True}
},
'confusion_matrix': {
'score_func': sklearn.metrics.confusion_matrix,
'kwargs': {'labels': [1, 0]}
},
'classification_report': {
'score_func': sklearn.metrics.classification_report,
'kwargs': {'output_dict': True, 'zero_division': 0}
},
},
'dataset': {
# Section level 'global' to specify common kwargs for test and train.
'global': {'targets_names': ['isFraud'],
'categor_names': [
'ProductCD', 'addr1', 'addr2', 'P_emaildomain',
'R_emaildomain', 'DeviceType', 'DeviceInfo',
*[f'M{i}' for i in range(1, 10)],
*[f'card{i}' for i in range(1, 7)],
*[f'id_{i}' for i in range(12, 39)]
],
'load__kwargs': {'nrows': 10000,
'index_col': 'TransactionID'},
},
'patch': {'merge': merge},
'train': {
'steps': [
('load', {'filepath': 'data/train_transaction.csv',
'key': 'transaction'}),
('load', {'filepath': 'data/train_identity.csv',
'key': 'identity'}),
('merge', {'left_id': 'transaction', 'right_id': 'identity',
'left_index': True, 'right_index': True,
'how': 'left', 'suffixes': ('_left', '_right')}),
('info',),
('preprocess',),
('split', {'train_size': 0.7, 'shuffle': False,
'random_state': 42}),
],
},
'test': {
'steps': [
('load', {'filepath': 'data/test_transaction.csv',
'key': 'transaction'}),
('load', {'filepath': 'data/test_identity.csv',
'key': 'identity'}),
('merge', {'left_id': 'transaction', 'right_id': 'identity',
'left_index': True, 'right_index': True,
'how': 'left', 'suffixes': ('_left', '_right')}),
('info',),
('preprocess',),
],
},
},
'workflow': {
'conf': {
# Global values will replace kwargs in corresponding default steps
# => easy switch between pipeline for example (pycnfg move unknown
# keys to 'global' by default).
'pipeline_id': 'pipeline__lgbm',
'dataset_id': 'dataset__train',
'predict__dataset_id': 'dataset__test',
'metric_id': ['metric__roc_auc', 'metric__precision',
'metric__custom'],
'validate__metric_id': ['metric__roc_auc', 'metric__precision',
'metric__custom',
'metric__classification_report',
'metric__confusion_matrix'],
'steps': [
('optimize', {'hp_grid': hp_grid_1,
'gs_params': 'gs_params__stage_1'}),
('optimize', {'hp_grid': hp_grid_2,
'gs_params': 'gs_params__stage_2',
'optimizer': mlshell.model_selection.MockOptimizer,
'resolve_params': 'resolve_params__stage_2'
}),
('optimize', {'hp_grid': hp_grid_3,
'gs_params': 'gs_params__stage_2',
'optimizer': mlshell.model_selection.MockOptimizer,
}),
('validate',),
('predict',),
('dump',),
],
},
},
# Separate section for 'resolve_params' kwarg in optimize.
'resolve_params': {
'stage_2': {
'priority': 3,
'init': {
'estimate__apply_threshold__threshold': {
'cross_val_predict': {
'method': 'predict_proba',
'cv': sklearn.model_selection.TimeSeriesSplit(n_splits=3),
'fit_params': {},
},
'calc_th_range': {
'samples': 10,
'plot_flag': False,
},
},
}
}
},
# Separate section for 'gs_params' kwarg in optimize.
'gs_params': {
'stage_1': {
'priority': 3,
'init': {
'n_iter': None,
'n_jobs': 1,
'refit': 'metric__roc_auc',
'cv': sklearn.model_selection.TimeSeriesSplit(n_splits=3),
'verbose': 1000,
'pre_dispatch': 'n_jobs',
'return_train_score': True,
},
},
'stage_2': {
'priority': 3,
'init': {
'method': 'predict_proba',
'n_iter': None,
'n_jobs': 1,
'refit': 'metric__custom',
'cv': sklearn.model_selection.TimeSeriesSplit(n_splits=3),
'verbose': 1000,
'pre_dispatch': 'n_jobs',
'return_train_score': True,
},
},
'stage_3': {
'priority': 3,
'init': {
'method': 'predict_proba',
'n_iter': None,
'n_jobs': 1,
'refit': 'metric__custom',
'cv': sklearn.model_selection.TimeSeriesSplit(n_splits=3),
'verbose': 1000,
'pre_dispatch': 'n_jobs',
'return_train_score': True,
},
},
},
}
if __name__ == '__main__':
# Use default configuration :data:`mlshell.CNFG`, that has pre-defined path
# logger sections and main sub-keys (see below)
objects = pycnfg.run(CNFG, dcnfg=mlshell.CNFG)
Results¶
Note
In second optimization stage
th_range came from ROC curve on OOF predictions for positive label.
Number of points set in resolve_params configuration. Positive label set either in dataset configuration, or auto-resolved as last one in np.unique(targets).
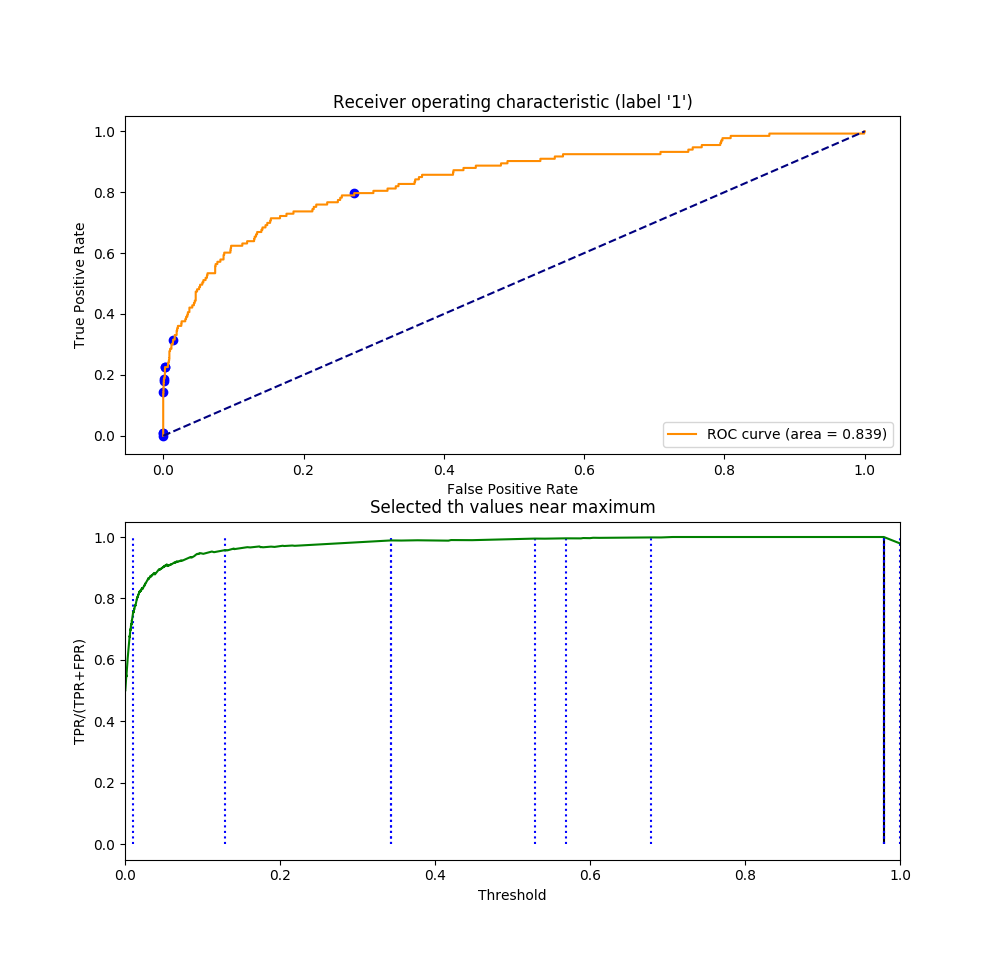
As expected: ROC AUC not depends on threshold (as evaluates on predict_proba).
Precision (and custom metric) depends on threshold. If positive class th_
close to 1, all samples classified as negative class (TP=0 and FP=0), so
precision become ill-defined, score set to 0 as specified in ‘zero_division’
argument fro precision metric.
In third optimization stage,
kw_argstunned for cutom score function.
There could be arbitrary logic.
see Concepts: classifier threshold for details.